The Context Window Is a Crutch: Why RAG-First Architectures Are Failing at Scale
The industry bet everything on RAG as the default knowledge architecture for LLMs. But at production scale — millions of documents, multi-tenant deployments, real-time updates — the cracks aren't just showing, they're structural. It's time to talk about what comes after.
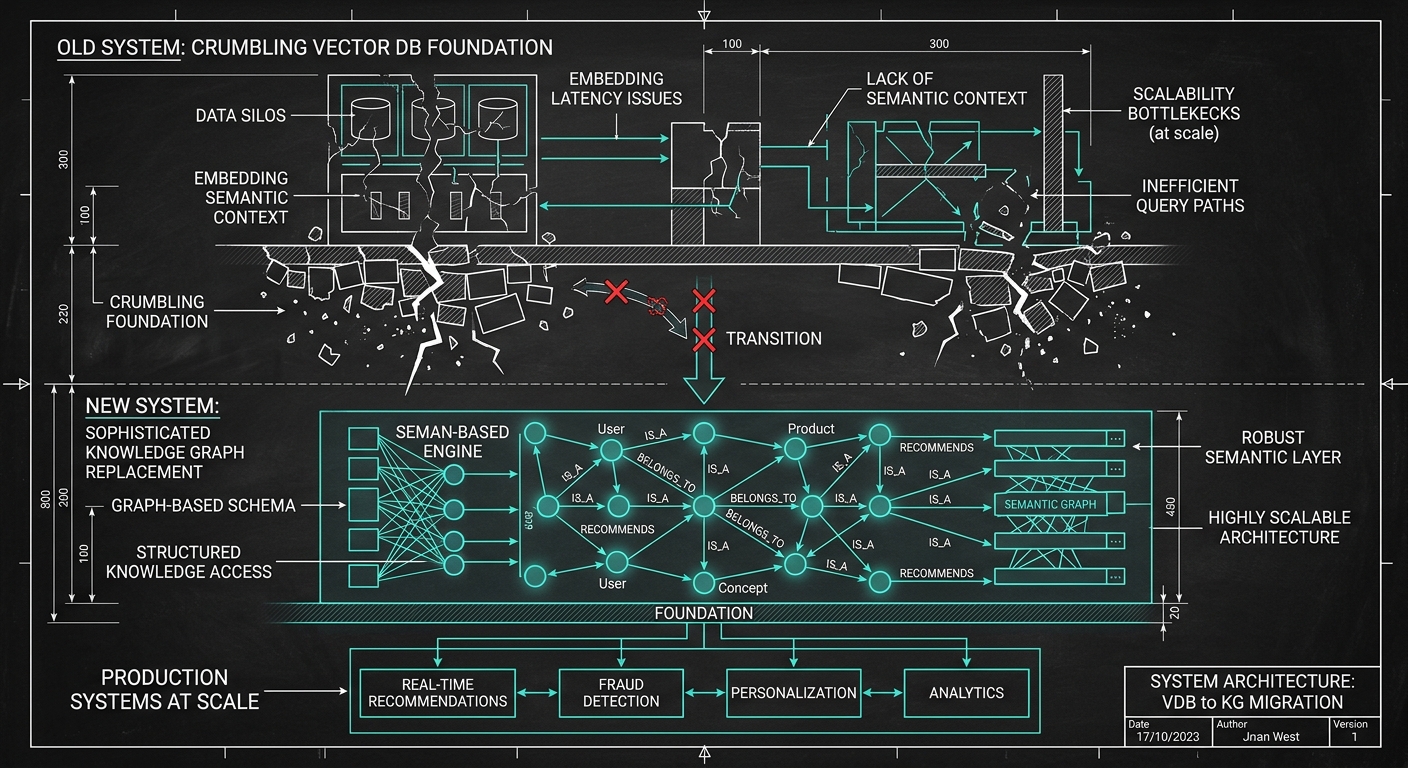
The RAG Hangover
Every enterprise AI team I talk to has the same story. They shipped a RAG prototype in two weeks. It demo'd great. Leadership greenlit production. And then, somewhere between 10,000 and 10 million documents, the whole thing started to rot.
Not catastrophically. That would be easy to diagnose. Instead, it rots slowly — answer quality degrades by a few percent per month, retrieval latency creeps up, users start complaining that "the AI used to be better," and engineers can't figure out why because every individual component still passes its unit tests.
This is the RAG hangover. And most teams are still drinking.
I've spent the last three years building and auditing knowledge architectures at scale — systems handling tens of millions of documents across multi-tenant enterprise deployments. The pattern is unmistakable: RAG was a necessary first step, but teams that treat it as the final architecture are building on sand.
This isn't a contrarian take for the sake of it. RAG solved a real problem at the right time. But the industry's collective failure to evolve past it is now the single biggest technical debt in enterprise AI.
Why Everyone Defaulted to RAG
Let's be honest about why RAG won the narrative war. It wasn't because it was the best architecture. It was because it was the most accessible one.
In 2023-2024, the pitch was irresistible:
- Simple mental model. Chunk your docs, embed them, store in a vector DB, retrieve top-k, stuff into context. Five steps. A junior engineer could ship it in a weekend.
- No fine-tuning required. You didn't need ML expertise, GPU clusters, or training pipelines. Just an embedding API and a vector database.
- Vendor-friendly. Every vector DB company, every cloud provider, every AI startup could sell you a piece of the RAG stack. The ecosystem exploded because it was modular and monetizable.
- Good enough for demos. With 50-100 documents and a friendly eval set, RAG produces impressive results. The failure modes only emerge at scale.
The result: RAG became the default architecture not because engineers evaluated alternatives, but because the entire ecosystem — tutorials, vendor docs, conference talks, open-source tools — converged on it as the "right way" to give LLMs access to your data.
We wrote about production-grade RAG patterns in our RAG architecture guide. That piece holds up. But the industry took "here's how to build RAG well" and heard "RAG is all you need." Those are very different statements.
Where RAG Breaks: The Five Failure Modes at Scale
Let me walk through the specific failure modes we see in production systems handling millions of documents. These aren't theoretical — they're patterns extracted from real deployments.
1. The Top-K Trap
This is the most fundamental problem and the one least discussed.
RAG retrieval works by finding the top-k most similar chunks to your query. Typical values: k=5 to k=20. The implicit assumption is that relevance is a simple similarity ranking and that the answer lives in the top few results.
At small scale, this holds. With 10,000 chunks, the signal-to-noise ratio is high enough that cosine similarity finds what you need. But at 10 million chunks, the embedding space gets crowded. You start seeing:
- Near-miss retrievals — chunks that are semantically adjacent to the answer but don't contain it. They score 0.82 similarity when the actual answer scores 0.84. The margin between useful and useless collapses.
- Topic clustering failures — when you have thousands of documents about similar topics (common in enterprise), the top-k results are often variations of the same information rather than complementary pieces.
- Recency blindness — vector similarity has no concept of time. A policy document from 2019 and its 2025 replacement score nearly identically against a query. Which one lands in your top-k is essentially random.
The fix isn't "just increase k." Increasing k means stuffing more tokens into the context window, which brings its own problems (more on that below) and increases latency and cost linearly. We've seen teams running k=50 or k=100 to compensate, burning $0.30+ per query on context tokens alone. That's not engineering. That's throwing money at a design flaw. We broke down the economics of this in our cost engineering deep-dive.
2. Embedding Drift
Here's something most teams don't discover until they've been in production for 6+ months: your embeddings are not stable over time.
Not because the embedding model changes (though that happens too — looking at you, API versioning). But because the corpus changes. When you add documents, the relative distances in embedding space shift. A chunk that was the nearest neighbor to a query six months ago may no longer be, not because it became less relevant, but because new chunks moved closer.
This is particularly brutal in enterprise environments where:
- Documents are updated frequently (policies, procedures, product specs)
- The corpus grows continuously (support tickets, meeting notes, reports)
- Different tenants have radically different document distributions
The result is silent quality degradation. No alerts fire. No errors are thrown. The system just gets worse. And because most teams don't have robust eval pipelines running continuously in production, they don't notice until users complain.
Re-embedding the entire corpus periodically is the brute-force fix, but at scale (millions of documents), that's a multi-day, multi-thousand-dollar operation. And it doesn't solve the underlying problem — it just resets the clock.
3. Context Window Pollution
This is the failure mode that inspired the title of this post.
The RAG thesis assumes that stuffing retrieved chunks into the context window gives the LLM what it needs to answer. But context windows aren't infinite attention machines. They're noisy channels with well-documented failure modes:
- Lost in the middle — LLMs disproportionately attend to the beginning and end of long contexts, underweighting information in the middle. If your answer is in chunk 4 of 10, it might as well not be there.
- Contradictory context — when retrieved chunks contain conflicting information (extremely common with versioned documents), the LLM has to arbitrate. Its arbitration strategy is opaque and unreliable.
- Distractor chunks — irrelevant but topically adjacent chunks don't just waste tokens. They actively degrade answer quality by polluting the attention distribution. The LLM now has to distinguish signal from noise, a task it's mediocre at when the noise is semantically similar to the signal.
The 1M+ token context windows that vendors are shipping don't solve this. They make it worse. Bigger windows mean teams stuff more garbage in, thinking more context equals better answers. It doesn't. A 200K context window full of marginally relevant chunks produces worse answers than a 4K window with precisely the right information.
The context window is a crutch. It lets you avoid the hard problem — figuring out exactly what information the LLM needs — by brute-forcing everything in and hoping attention mechanisms sort it out. They don't.
4. The Chunking Catastrophe
Every RAG tutorial starts with "chunk your documents." None of them adequately address how catastrophically bad naive chunking is for real documents.
Fixed-size chunking (500 tokens, 1000 tokens, whatever) is the most common approach and the most destructive. It breaks:
- Tables — split across chunks, losing row-column relationships
- Lists — items separated from their headers
- Cross-references — "as described in Section 3.2" becomes meaningless when Section 3.2 is in a different chunk
- Conditional logic — "If condition A, then X. If condition B, then Y" split across chunks loses the conditional structure
- Multi-page reasoning — any argument that spans more than your chunk size gets dismembered
Semantic chunking (splitting on topic boundaries) helps but doesn't solve the fundamental issue: documents are structured artifacts with internal relationships that chunking destroys. A contract isn't a bag of paragraphs. A technical specification isn't a collection of independent statements. Treating them that way is information destruction.
We've seen teams spend months building increasingly sophisticated chunking pipelines — recursive splitters, LLM-based chunkers, format-specific parsers — only to realize they're optimizing a fundamentally broken abstraction.
5. Multi-Tenant Isolation Failures
This one keeps CTOs up at night, and rightfully so.
In multi-tenant RAG systems, you're typically sharing a vector database across tenants with metadata-based filtering. The retrieval query becomes: "find top-k chunks similar to this query WHERE tenant_id = X."
The problems:
- Filter-then-rank vs. rank-then-filter — these produce different results, and which one your vector DB uses may not be obvious. Filter-first can miss relevant results if the index structure doesn't align with your filter patterns. Rank-first can leak cross-tenant information into similarity scores.
- Embedding space contamination — in shared embedding spaces, one tenant's documents influence the nearest-neighbor relationships for other tenants. Adding a million documents for Tenant A can degrade retrieval quality for Tenant B, even though their data never mixes.
- Uneven corpus sizes — when Tenant A has 50K documents and Tenant B has 5M, the embedding space is dominated by Tenant B's distribution. Same top-k, radically different retrieval quality.
The "just use separate collections per tenant" approach doesn't scale. At 1000+ tenants, you're managing thousands of separate indices, each with its own memory footprint, each requiring independent optimization.
What to Build Instead: Beyond the RAG Monoculture
If RAG-first is failing, what's the alternative? Not a single replacement — that would be repeating the same mistake. The answer is heterogeneous knowledge architectures that use the right retrieval strategy for each type of knowledge.
Pattern 1: Knowledge Graph-Augmented Retrieval
The most impactful upgrade for most enterprise systems is adding a structured knowledge layer alongside (not replacing) vector retrieval.
The architecture:
- Ingest pipeline extracts entities and relationships from documents, building a knowledge graph (Neo4j, Amazon Neptune, or even PostgreSQL with recursive CTEs for simpler cases).
- Query analysis determines whether the query needs factual lookup (graph), semantic search (vectors), or both.
- Graph traversal retrieves structured facts and their provenance chains.
- Vector retrieval fills in context for open-ended or nuanced questions.
- Fusion layer combines graph facts and vector chunks into a coherent context.
Why this works: knowledge graphs preserve relationships that chunking destroys. "Who approved this policy?" is a graph query, not a similarity search. "What's the relationship between Product X and Regulation Y?" requires traversing explicit connections, not hoping the right chunks land in your top-k.
We explored the knowledge layer concept extensively in our piece on escaping the data lakehouse trap. The core insight: your data infrastructure needs a semantic layer that understands what things are and how they relate, not just what they're near in embedding space.
The overhead is real — entity extraction pipelines, graph maintenance, query routing logic. But the payoff is dramatic: we've seen 40-60% improvements in answer accuracy on structured queries after adding a graph layer to existing RAG systems.
Pattern 2: Agentic Memory Architecture
This is the pattern I'm most bullish on for 2026 and beyond.
Instead of a static retrieve-then-generate pipeline, build an agent that manages its own memory. The architecture:
- Working memory — the current context window, managed explicitly rather than stuffed blindly
- Episodic memory — a structured log of past interactions, retrievable by recency, relevance, or importance
- Semantic memory — long-term knowledge, stored in a combination of vector indices and structured stores
- Procedural memory — learned strategies for how to retrieve and use information effectively
The agent doesn't just retrieve; it reasons about what it needs to know, formulates targeted retrieval strategies, evaluates retrieved information for relevance, and iteratively refines its context.
This is fundamentally different from RAG. In RAG, retrieval is a single-shot function: query in, chunks out. In agentic memory, retrieval is an ongoing process where the agent actively manages what information it holds, discards, and seeks.
We laid out the full architecture for this in our enterprise agent memory piece. The key insight: memory isn't a database query. It's a cognitive function that requires planning, evaluation, and adaptation.
Concrete implementation: instead of retrieve(query) -> chunks -> generate(chunks), you build:
plan_retrieval(query, current_context) -> retrieval_strategy
execute_retrieval(strategy) -> candidate_information
evaluate_relevance(candidates, query) -> filtered_information
check_sufficiency(filtered, query) -> sufficient | need_more
if need_more: refine_strategy() and loop
compose_context(filtered) -> optimized_context
generate(optimized_context) -> response
More complex? Yes. More expensive per query? Initially. But the accuracy improvements are substantial, and the cost curve inverts quickly because you're retrieving less total information with higher precision.
Pattern 3: Structured Retrieval with Query Decomposition
Many enterprise queries aren't single questions. They're compound queries that require multiple retrieval passes.
"Compare our Q3 and Q4 performance in the EMEA region and identify the top factors driving the difference."
A single vector search on this query is almost useless. You need:
- Retrieve Q3 EMEA performance data
- Retrieve Q4 EMEA performance data
- Retrieve analysis or commentary on EMEA performance drivers
- Synthesize across all three
Query decomposition breaks compound queries into atomic retrieval operations, each targeted at a specific information need. This is table stakes in search engineering but somehow got lost in the RAG gold rush.
Implementation: use an LLM to decompose the user query into sub-queries, execute each independently (potentially against different indices or data sources), then compose the results.
This connects directly to the compound AI system patterns we've written about. The key principle: complex information needs require orchestrated multi-step retrieval, not single-pass similarity search.
Pattern 4: Hybrid Retrieval with Learned Routing
The most sophisticated architecture we deploy combines multiple retrieval strategies with a learned router that selects the right strategy per query.
The retrieval backends:
- Vector search — for open-ended, semantic queries
- BM25/keyword search — for exact match, terminology-specific queries (consistently underrated)
- Knowledge graph traversal — for relationship and entity queries
- SQL/structured query — for quantitative, tabular, or aggregation queries
- Temporal retrieval — for time-sensitive queries with recency requirements
The router is a lightweight classifier (fine-tuned on your query logs) that predicts which backend(s) to invoke and how to combine results. It learns from user feedback: when users rephrase queries or rate answers, that signal trains the router.
This architecture treats retrieval as a routing problem, not a one-size-fits-all pipeline. Different questions need different retrieval strategies. The "embed everything, retrieve by similarity" approach is like using a hammer for every fastener — it works for nails but destroys screws.
Anti-Patterns to Kill Immediately
If you're running RAG in production, here are the patterns you should deprecate today:
The "Stuff and Pray" pattern. Retrieving top-20 chunks and concatenating them into the context with no relevance filtering, no ordering strategy, and no deduplication. This is the most common pattern and the most wasteful.
The "One Index to Rule Them All" pattern. A single vector index for all document types, all tenants, all use cases. Different document types have different embedding characteristics. A support ticket and a legal contract should not live in the same embedding space with the same retrieval parameters.
The "Embed Once, Retrieve Forever" pattern. No re-indexing strategy, no drift detection, no quality monitoring. Your embeddings are stale. You just don't know it yet.
The "Bigger Context Window" pattern. Compensating for retrieval quality problems by using larger context windows. You're increasing cost and latency while often decreasing answer quality. The solution to bad retrieval is better retrieval, not more context.
The "Chunk Size Tuning" pattern. Spending weeks A/B testing chunk sizes (256 vs 512 vs 1024 tokens) as if this is the key variable. It's not. The problem is chunking itself. Invest that time in document understanding and structured extraction instead.
The Migration Path: RAG to Knowledge Architecture
You can't rip out RAG overnight, nor should you. Here's the pragmatic migration path:
Phase 1: Instrument and Measure (Week 1-2)
Add retrieval quality metrics to your pipeline. Track: retrieval precision (what fraction of retrieved chunks are actually used in the answer), answer faithfulness (does the answer follow from the context), and query-level failure rates. You can't improve what you can't measure.
Phase 2: Add Re-ranking (Week 2-4)
Drop a cross-encoder re-ranker between retrieval and generation. This is the single highest-ROI improvement for existing RAG systems. Retrieve top-50 with vector search, re-rank to top-5 with a cross-encoder. Dramatic quality improvement, moderate latency increase.
Phase 3: Implement Query Decomposition (Month 2)
Add an LLM-based query analyzer that decomposes compound queries and routes simple queries directly. This catches the 30-40% of queries that RAG handles poorly because they're multi-hop or comparative.
Phase 4: Build the Knowledge Layer (Month 2-4)
Start extracting entities and relationships from your highest-value document collections. Build a knowledge graph alongside your vector indices. Route entity/relationship queries to the graph.
Phase 5: Agentic Retrieval (Month 4-6)
Replace the static retrieve-generate pipeline with an agent that plans retrieval, evaluates results, and iteratively refines its context. This is the endgame architecture.
Each phase delivers measurable improvement. You don't need to wait for Phase 5 to see results. But you do need to start moving, because your competitors are.
The Bigger Picture
The RAG-first era was necessary. It got millions of developers building LLM applications, created a massive ecosystem of tools and infrastructure, and proved that grounding LLMs in external knowledge is essential.
But we're past that now. The teams that will win in 2026-2027 are the ones building knowledge architectures — purpose-built systems that understand the structure, relationships, and temporal dynamics of their information. Not just bags of vectors with a similarity search on top.
The context window is a crutch. A useful crutch during recovery, but a liability if you never learn to walk without it. The teams still leaning on it are building increasingly expensive, increasingly fragile systems that will be outperformed by architectures designed around precision retrieval, structured knowledge, and agentic memory.
RAG got us here. It won't get us where we need to go.
If your team is navigating this transition, we'd love to talk. We've helped enterprises across financial services, healthcare, and technology migrate from RAG-first to knowledge-first architectures — and the performance improvements speak for themselves.
Founder & Principal Architect, Bigyan Analytics
Ready to explore AI for your organization?
Schedule a free consultation to discuss your AI goals and challenges.
Book Free Consultation